Structure
Sample Chapter
Reference Material
Last Update 12th January 2020
Service Provision -
Technologies for Next Generation
Communications Systems

|
Contents
Introduction
Structure Sample Chapter Reference Material Last Update 12th January 2020 |
Service Provision -
|
The following sample chapter is provided as a courtesy by John Wiley and Sons © 2004, all rights reserved. The typographical standard of the actual book is of course much better than this web page.
The impact of Internet Technology on the communication industry has been large. However, it is not really clear what the Internet means. Originally the Internet was assumed to be the world-wide IP (Internet Protocol) network. Recently the meaning has, at least in popular media, changed towards everything running on top of IP, such as email or the WWW (World Wide Web). What this change in meaning indicates is the interest of people in the service and in what they get from the Internet compared to how the technology is implemented.
This chapter mainly addresses service issues in IP-based environments. The term service is one of these terms saying everything and nothing. In the case of Internet Services we can basically differentiate between transport services, such as the Integrated Service Architecture or the Differentiated Service Architecture, and end-system services such as Web services, email services and voice services. Both types of service are covered in this chapter.
Figure 5.1 shows the area covered in the rest of the chapter. The figure shows an example scenario covering enterprise, core, and home networks running Voice over IP calls between all these parties.
The IP network provides the basic transport service, including various types of transport service guarantees. The technologies are meant to operate in core networks and in larger enterprise networks.
Voice over IP can be regarded a service running on top of the IP-based infrastructure. It runs a specific signaling protocol for setting up voice calls. The Voice over IP signaling protocol is independent of network-level signaling. It just uses the IP infrastructure for transporting the signaling messages and for transporting the encoded voice.
A directory-enabled network runs several enterprise internal services including databases, email, and other distributed applications. It is still based on IP network technologies together with some QoS (Quality of Service) technologies. The enterprise services are controlled and managed via several independent applications, but using the same directory to read and write management data.
The home network on the other hand has the requirement that it must run without sophisticated management tools and applications, but in a heterogeneous networking environment.
Finally, the last section in the chapter will give an outlook on networking research. This part, not shown in Figure 5.1, tries to integrate the different requirements in one very flexible approach. These new developments are termed active networking technologies.
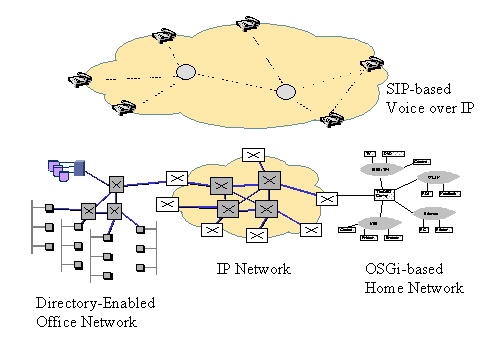
Figure 5.1: Overview of Internet Areas
The premier standardization body for Internet technology is the IETF (Internet Engineering Task Force,�(Bradner 1996)). It operates in an open fashion allowing everybody to participate. It consists of a large set of working groups, each having an open mailing list to which anyone can subscribe and contribute. Additionally, three times a year IETF face-to-face meetings are organized to quickly sort out disagreement and solve problems.
IETF�documents include Internet Drafts, which are proposals and working documents without formal significance. Then there are RFCs (Requests for Comments), which are documents agreed upon by the working group as well as by the IESG (Internet Engineering Steering Group). As soon as a document achieves the status of an RFC, it means it is ready for implementation. RFC are classified according to whether the content is really a standard (standards track), informational, or experimental. If an RFC is on the standards track, three stages are passed through. First it is called a Proposed Standard, which means the proposal can be implemented. The second state is Draft Standard as soon as two interoperable independent implementations are available and tested. Finally, the document eventually becomes a Full Standard if, and only if, the technology is widely deployed.
In this section several standardized approaches are covered in order to guarantee the quality of a transport service, often called QoS (Quality of Service). The difficulty starts when trying to define what quality is. Does quality lie in the guaranteed rate of bytes transported, or more in the time the service is available and accessible? Quality of Service is discussed from a service management perspective in chapter 8. The IETF�standardized approaches follow more the notion of short-term quality such as bandwidth guarantees.
The plain old IP service is called a best-effort service since no bandwidth or delivery guarantees are provided. However, at a closer look the plain old IP service does have some quality attributes as well. The service guarantees fairness in the sense that no packets are preferred over others. Additionally, TCP (Transmission Control Protocol) provides fairness in terms of bandwidth used by TCP sessions. All TCP session running over the same link share the link capacity in a fair way. This type of fairness has been undermined by some application using several TCP sessions, e.g. for file download. Other types of transport protocols such as UDP (User Datagram Protocol) do not provide this fairness.
Another feature of the IP architecture is its relative robustness against node and link failures. At least in the networks running dynamic routing protocols, the transport service recovers from failures by learning the new network topology and forwarding traffic according to the new calculated routes.
Concerning bandwidth guarantees, many people believe that they are not needed since there is enough capacity available anyway. The argument for the so-called over-provisioning of capacity is as follows. It is much cheaper to add more capacity to the network compared to adding management and control complexity in order to avoid bottlenecks and to provide guaranteed services. So, sound network planning on a long timeframe provides QoS�by increasing the capacity at bottleneck links in advance. Additionally, a sound topology can optimize packet latency mainly by a more meshed topology for the network.
Nevertheless this approach is not practical for certain environments, and might be a short-term solution only. Environments where plain old IP does not solve the problems are cases where the link technology is expensive, such as wireless networks. Also in environments where stringent delay, loss, jitter, and bandwidth guarantees are required, plain old IP has limitations. Finally, there might be business opportunities providing a whole range of different customized transport services.
The first approach that tried to include Quality of Service features in IP networks was called IntServ (Integrated Services (Braden et al., 1994)).�The idea was to operate only one single integrated network instead of several dedicated ones. The additional feature required is the ability to run real-time applications such as multimedia applications over the Internet.
The Integrated Service Architecture was built for individual application instances to request resources from the network. This implies that per-flow handling is proposed, so every router along an application�s traffic path needs per-flow handling of traffic. An IntServ flow is defined as a classifiable set of packets from a source to a destination for which common QoS�treatment has been requested.
In order to let an application communicate with the network and to configure the network to provide a certain service, some sort of signaling is required. Firstly the application needs to request a transport service from the network; secondly the service needs to be provisioned. The signaling protocol for the IntServ Architecture (Wroclawski 1997) is RSVP (Resource Reservation Protocol,�(Braden et al. (1997)). It provides both functions at the same time. However note that the IntServ architecture is too often directly associated with RSVP. RSVP can also be used for other types of QoS�and non-QoS signaling.
In the following we provide a short summary of RSVP�as the only IP-based signaling protocol. RSVP establishes resource reservations for a unidirectional data flow. RSVP is classified as hop-by-hop protocol, which means that RSVP communicates with all routers on the data path in order to set up a particular service.
A feature that makes the protocol simpler, but also limits its applicability in certain environments, is that it is independent of the routing protocol. So no QoS-based�routing can be implemented.
In RSVP�the data sender advertises QoS�requirements, because the sending application most likely knows the data flow requirement best. This advertisement message searches the path through the network to the destination. All entities along that path know then the sender�s capability and QoS requirement, and they can change this specification if they are not able to provide the required service.
Eventually, the destination is made aware of the requirement and can adapt it to its capabilities. This is the point where the real reservation starts. The reservation is performed starting at the data receiver, so RSVP�is often called a receiver-oriented signaling protocol.
One of the biggest problems for signaling protocols is state management. This denotes the function of deleting unused state, in this case reservations no longer valid. Since the Internet is an inherently unreliable network, RSVP�has chosen a soft-state approach. This means that state has significance for a certain time only; afterwards it needs to be refreshed in order to stay alive. This approach allows RSVP to gracefully handle error situations, which happen often in unreliable networks. It also handles routing changes in the same way.
Figure 5.2 shows the basic RSVP�operation. The PATH message contains the QoS�requirements and searches the path through the network. The RESV message is what really reserves the resource on each node for that particular service. After that operation, the sender can start sending data and obtain the guaranteed service. Since RSVP is a soft-state type of protocol, periodic refreshes are used to keep the reservation valid. Finally, RSVP tear-down closes the session.
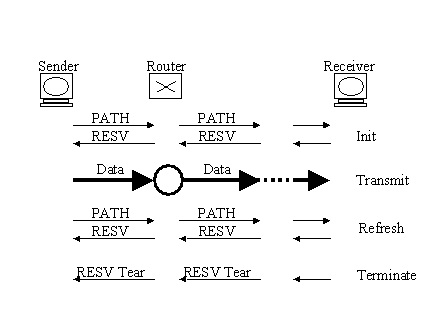
Figure 5.2: Basic RSVP Operation
RSVP�also has its drawbacks. It is regarded as fairly complex, because both one-to-one and multicast applications are supported. Additionally, the design of RSVP has scalability problems for a large number of flows, which appear in the core of the network.
From a transport service point of view two services, the Controlled Load and the Guaranteed Service, have been defined. It is possible to define other services, but none has been standardized so far.
The Guaranteed Service provides firm (mathematically provable) bounds on end-to-end packet queuing delays. This service makes it possible to provide a service that guarantees both delay and bandwidth (Shenker et al. 1997).
The Guaranteed Service�is more suitable for intolerant real-time applications. These applications implement a play-out buffer whose size is bounded by the worst-case jitter, which in turn is bounded by the worst-case delay. The service does not guarantee any average or minimum latency, average jitter, etc. The application must provide the characteristics of its expected traffic. The network calculates and returns an indication of the resulting end-to-end latency and whether the service can be guaranteed. The delay is computed from the link delay plus the queuing delay, where the queuing delay again depends on the burst size.
The service parameters include the sending rate and the burst size together with the requested delay bound. The network guarantees timely delivery of packets conforming to the specified traffic (rate and burst size). From a service provider perspective this service allows for almost no multiplexing, which makes this service relatively expensive.
The Controlled Load Service�basically provides a service similar to that provided when the links are unloaded (Wroclawski(1997). Unloaded conditions are meant to be lightly loaded networks or not congested networks. The service requires the packet loss to approximate the basic packet error rate of the underlying transmission system. The transit delay of most of the packets should not exceed the minimum transit delay (sum of transmission delay plus router processing delay).
The Controlled Load Service allows applications to get a good service, but not a fully guaranteed service. From a service provider point of view, this allows for a higher degree of multiplexing compared to the Guaranteed Service.
One characteristic of the Integrated Services model is that routes are selected based on traditional routing. This means that packets follow the normal path. Reservations are made on that path, or they are rejected if no resources are available on that path. Therefore IntServ does not provide QoS�routing capabilities. QoS routing is a mechanism where the path is chosen according to the required service characteristics. The reasons for this decision are that it is in general not possible to force packets to follow non-shortest paths (see later for a discussion on how MPLS provides that function), and that QoS routing algorithms are very complex and still not well understood.
The most severe problem of the Integrated Service approach is that it is not suitable for backbone networks. The reason is that each flow is handled separately on the signaling (control) plane and on the data plane, which implies millions of flows in backbone routers at the same time. The algorithm to handle flow separation does not scale well to these high numbers of flows. Also RSVP�has some scalability problems for a large number of flows, mainly in terms of processing capacity and memory used.
As an answer to the previously mentioned scalability problems for the Integrated Service approach, DiffServ (Differentiated Service) was developed. Compared to IntServ it breaks with end-to-end significance, is more incremental to the existing Internet, and is simpler. Scalability is achieved because DiffServ does not deal with individual flows, but with CoS (Classes of Service). All traffic is mapped to a small set of traffic classes when entering the DiffServ network.
The basic design goal of DiffServ is to perform the expensive data plane functions at the edge of the network, and to keep the core router functionality very simple. The core routers basically maintain a small number of service classes with defined per-router behavior called Per-Hop Behavior�(PHB). The edge routers classify incoming packets into one of these service classes, and perform policing and traffic shaping. Policing refers to the function of checking whether a traffic stream conforms to a negotiated rate, and if not, then dropping packets of that stream. Traffic shaping refers to the function of making the traffic conformant by buffering. Basically, it equalizes short-term variations within a flow.
Figure 5.3 shows a conceptual model of the functionality on an edge router. An edge router classifies packets based on several IP packet header fields such as source and destination address, source and destination port number, and protocol type. It then marks the IP packet with a so-called DSCP (DiffServ Code Point), which is a replacement of the original IP header field ToS (Type-of-Service). The traffic may then be policed or shaped. For instance, a token bucket policer would drop all packets not conforming to the token bucket parameters.
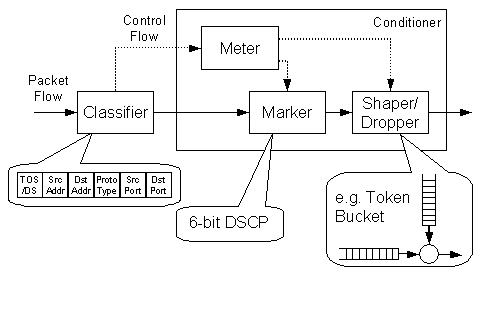
Figure 5.3: Example DiffServ Edge Router
In the core routers the packets are then classified based only on the DSCP and handled according to the defined Per-Hop Behavior. Figure 5.4 shows an example core router configuration. Packets are classified based on the DSCP�value in the ToS field. Depending on the local DSCP to PHB mapping, the packets are placed in separate queues. This is where the differentiation of packets takes place.
The example configuration runs a priority queue, where all EF packets (Expedited Forwarding, see below) are handled with explicit priority over the others. Then five queues share the rest of the bandwidth using, for example, weighted round-robin scheduling. Within the queues for AF traffic (Assured Forwarding), algorithms take care of the drop precedence if the queues are filling up. See below for a description of Per-Hop Behaviors.
This example shows that in core routers no policing and shaping happen. The classification based on a few possible values of the DSCP�is much simpler. Finally, the packet scheduler with only six queues in the example is far more efficient compared to one with millions of queues.
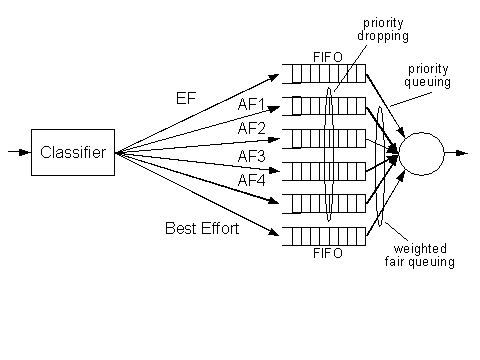
Figure 5.4: Example DiffServ Core Router Configuration
The relationship between the PHB�and DSCPs is mainly of operational interest, because a network administrator can choose the DSCP�to PHB mapping freely. However, all PHBs have default/recommended DSCP values.
There are currently three PHBs standardized: the Class Selector PHB, the Expedited Forwarding PHB, and the Assured Forwarding PHB. Additionally there is the best-effort PHB, but this is the normal IP behavior and is not further discussed here.
The Class Selector PHB�is partially backward compatible with the definition of the ToS field in the IP header. Nichols defines the behavior with the following rules (Nichols 1998). Routers should give packets the same or higher probability of timely forwarding compared to packets with a lower order Class Selector Code Point.
The EF PHB for Expedited Forwarding (Davie et al. 2002) is simple high-priority packet handling. It defines that routers must service packets at least as fast as the rate at which EF PHB packets arrive. The definition is pretty open, but in reality a priority scheduler processing packets from the EF queue with highest priority can easily achieve this PHB. Other scheduling disciplines are useful also. the handling rate must be equal to or greater than the expected arrival rate of EF marked packets.
�The AF PHB�for Assured Forwarding (Heinanen et al. 1999) is actually a whole group of PHBs. The group can have a number of PHB classes. Within a class a number of drop-precedence levels are defined. The number of classes is normally four, and the number of levels three. The class really defines a certain service class into which packets at the edge of a DiffServ node are classified. The drop-precedence level defines which packets should be dropped first compared to other packets of the same class in the case of overloaded links. More intuitively we can talk about colored packets and mean the drop precedence. For example, packets can be marked green, yellow, and red. Packets marked red have a higher drop probability compared to packets marked with yellow, and these in turn have a higher drop probability than the packets marked green.
Given the basics of DiffServ, it is possible to consider the types of transport services that can be provided. The services can be classified along several dimensions. Firstly, based on duration a service can be regarded as dynamically provisioned or statically provisioned. Secondly, a service can be guaranteed quantitative (constant or variable), qualitative, or relative. Thirdly, the traffic scope may include point-to-point, one-to-any, or one-to-many (multi-cast). For one-to-any the ingress node for the DiffServ domain is known, but the egress node is not known and can be any node. It also means that traffic with different destinations at a particular point in time is present in the network.
In order to provide guaranteed quantitative transport service, an admission control function must be added to the network. Normally this is handled by a QoS�management system that is responsible for the network configuration and for further QoS management functions. This kind of QoS management system is normally called a QoS Server�or a Bandwidth Broker.
The QoS�server performs connection admission control to the traffic class. It is aware of current routing tables and may modify them (QoS routing). It is also aware of all reservations concerning the particular traffic class. Furthermore, the QoS server is responsible for the proper configuration of the QoS-related components on all routers of the network, including traffic shapers, traffic classifiers, and schedulers.
This QoS�management system is normally thought of as centralized entity, but it does not need to be. The system is able to deal with only a limited number of reservations, which means reservations are more based on aggregated traffic than on single small flows.
�Nevertheless the granularity of reservation is mainly a decision of the network provider, and depends also on the maximum number of service requests a QoS�management system can handle. The question of how dynamic service requests can be impacts the QoS server performance as well.
There was an effort in the IETF�DiffServ Working Group to standardize services that are called Per-Domain Behavior (PDB) in their terminology. Compared to the term Per-Hop Behavior, which defines the behavior of packets at a router, the PDB defines the behavior of packets or flow passing through a complete DiffServ domain. The idea behind this was to define services using the DiffServ components available. However, the standardization effort was stopped because it was very difficult to find many different services with predictable behavior.
As described above, there are also services with qualitative and relative guarantees. These are typically provided in a static way and are normally bound to a service contract. Additionally, they often do not need even admission control.
The two most
frequently cited services are the Premium Service and the Assured Service. A
third one presented here is called Better than Best-
Effort service.
The Premium Service is a service with bandwidth guarantee, bounded delay, limited jitter, and no packet loss. It is provided in a DiffServ network with the EF PHB, which gets preferred handling in the routers. Access to the EF traffic class must be controlled, and must be checked for each new connection. Strict policing of flows at the DiffServ edge mainly performs this. A strict policer means a policer that drops all packets not conforming to the negotiated bandwidth. Additionally, admission control needs to be performed. Admission control functions check whether there is still enough capacity available to accommodate a new service request. This requires a global view of the network, including routing tables, network resources, and all current reservations. Only if access to the network is controlled can a guaranteed Premium Service be provided.
The Assured Service is less stringent in its guarantee that it provides. It mainly defines a service with assured bandwidth guarantees and with near-zero loss for packets conforming to the committed rate. Packets that exceed the committed rate are not lost if enough capacity is available.
This service can be implemented with the Assured Forwarding PHB and a so-called two-color marker at the edge router. This entity marks packets conforming to the committed rate with green; packets above that rate are marked with yellow. If a three-color marker is used, a second maximum rate can be a service parameter; all packets above the maximum rate are marked red. Coloring is implemented with the drop precedence feature of the Assured Forwarding PHB.
In the admission control function, the committed rate is checked against availability in order to guarantee near zero-loss. If a link is congested, the red packets are dropped. If the link becomes more congested, the yellow packets are also dropped to give green packets preferred handling within an Assured Service class.
The Better than Best-Effort service can be classified as a typical relative guaranteed service. The easiest implementation uses the Class Selector PHB, which defines priority of classes. So all traffic having a static Better than Best-Effort service gets a higher priority than that of the Best-Effort class. There are no quantitative guarantees with such a contract, only the provision that traffic gets better service compared to Best-Effort service traffic.
Other services are possible as well, combining the different components freely to obtain different behavior.
Basic DiffServ scales very well, but it does not provide sufficient means for providing certain types of QoS. It often needs to be coupled with a QoS management system. Typically, this has a negative impact on the scalability of the DiffServ approach. The challenge is designing it in a way that keeps scalability as high as possible.
We also need to consider the time required for all these configuration actions, when the QoS�server receives per-flow requests from individual applications. This solution has a significantly lower scalability than basic DiffServ, and it would not be feasible for a core network. In order to make such a system reasonably scalable, some aggregation of requests is necessary.
In general, the Differentiated Services Architecture is useful for a backbone network, giving guarantees for traffic aggregates instead of single application flows. In other environments, DiffServ makes sense from a business point of view. It allows service providers to differentiate individual customers and various service offerings, where a more expensive service obtains better treatment.
From a management point of view, the open definition of DiffServ provides problems. It allows for too many very flexible solutions. It is therefore difficult to achieve an interoperable solution with equipment and software from different vendors.
MPLS (Multi-Protocol Label Switching) is not directly a QoS�technology, but it can support QoS provisioning by extending IP routing. With MPLS, IP packets are labeled when entering the MPLS network and they then follow a fixed LSP (Label Switched Path).
The major features of MPLS are as follows IP Packets belonging to an LSP are forwarded based on a short label (label switching) instead of being based on the longest-prefix address lookup (IP routing). This simplifies and speeds up forwarding. The label itself has only per-link significance, and can be changed on each node along a path.
IP Packets can be routed explicitly by fixing the route of an LSP. An LSR (Label Switching Router) examines the label on each arriving packet and handles the packet accordingly.
Figure 5.5 shows the basic architecture of MPLS. At edge nodes packets are classified and labeled. Then they are sent according to the local LSR configuration towards the next hop based on the label. In the core, labels are then the only way to find the way through the network.
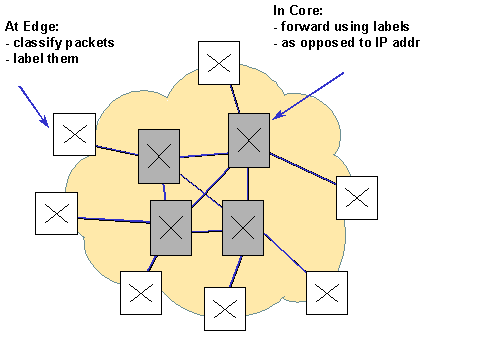
Figure 5.5: MPLS Architecture
With packet labeling based on packet classification, packets can be assigned to LSPs on a per-flow basis. This is particularly interesting because there can be several LSPs between a pair of edge nodes, with different QoS�characteristics or just for load balancing.
MPLS can be used for providing QoS�when combined with other QoS technologies. For example when run over ATM (Asynchronous Transfer Mode), MPLS can map LSPs to ATM virtual connections and provide IP QoS per LSP based on ATM QoS. Another example is combining MPLS with DiffServ. Using different LSPs for different Classes of Service allows routing the classes individually. Additionally, routing traffic along less used paths and around bottlenecks provides better quality of the service.
A label distribution protocol is used for setting up Label Switched Paths. Label distribution protocols are a set of procedures by which one LSR informs another of the label and/or FEC (Forward Equivalence Class) bindings it has made. Note that FEC binding denotes the traffic carried by a certain label. The label distribution protocol also encompasses any negotiations in which two neighboring LSRs need to engage in order to learn of each other's MPLS capabilities.
MPLS is not a QoS�technology per se, but provides functionality that makes QoS networking easier. Basically, QoS can be more easily provided through fixing paths. Monitoring the network and directing traffic around bottlenecks achieve some quality as well.
On the other hand, it is questionable whether adding another layer below IP is a good choice. It adds management complexity because an additional technology needs to be managed. It also adds some overhead for the networking layer. Finally, it relies on IP because the complete control plane (signaling for label distribution and routing protocols) is based on IP standards.
Several different architectures can be considered under the heading of Internet Telephony. Some people regard an IP transport network between central offices as already Internet telephony. The other extreme case is people using IP-capable telephones for voice with IP protocols only. In this section we mainly cover the second case. Different technologies for IP telephony will be discussed, mainly those that are based on the SIP (Session Initiation Protocol).
The PSTN (Public Switched Telephone Network)�makes use of two very distinct functional layers: the circuit-switched transport layer and the control layer. The circuit-switched layer consists of different types of switches. The control layer consists of computers, databases and service nodes that control the behavior of circuit switches and provide all the services of the PSTN. All the signaling traffic used for control travels over a separate signaling network. The main characteristics from a high-level point of view are that the network contains most of the intelligence and the terminals are relatively dumb. From a service point of view, the service logic needs to be handled within the network and is under control of the provider.
The Internet on the other hand is a packet-based network, where the network has only minimal functionality and the terminal nodes are reasonably intelligent. From the service point of view this means that the service logic can be located on end-systems. This is in principle a very competitive situation because anybody can easily provide any kind of IP-based services.
Internet Telephony�is meant to be cheaper than conventional telephony. However, in many respects it is cheaper only because the quality and reliability are lower than in traditional telephony. Another oft-stated benefit is the integration of telephony into other types of computer communication such as Web services, email, CTI (Computer-Telephony Integration), etc. There are also some challenges for Internet Telephony. Quality of Service must be established to guarantee certain voice quality. Internet Telephony must also be integrated with the existing PSTN architecture, including call signaling.
The SIP (Session Initiation Protocol, Rosenberg et al. (2002)) is a signaling protocol developed by the IETF to control the negotiation, setup, tear-down, and modification of multimedia sessions over the Internet. It is, together with H.323�(ITU 1996b), a candidate for becoming the standard signaling protocol for IP Telephony. However SIP is not restricted to IP telephony, as it was designed for general multimedia connections.
SIP�entities include user agents at terminals and proxy servers. A SIP user agent consists of a user agent client and a user agent server, sending requests to other SIP entities or replying to received requests respectively. SIP proxy servers route SIP messages between different domains and resolve SIP addresses. Figure 5.6 shows a simple example SIP message flow.
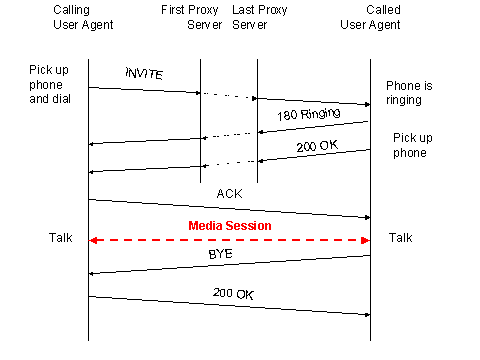
Figure 5.6: Example SIP Message Flow
In this example a caller�s user agent sends a SIP�INVITE request to a proxy server. The proxy server (and potentially several further proxy servers) locates the callee by looking up call forwarding tables or other routing information, and forwards the message to the callee�s SIP user agent. If this one accepts the call, it starts ringing while waiting for the callee to pickup the handset. This is indicated to the caller by the 180 RINGING reply, which generates a ringing tone in the caller�s terminal. A 200 OK reply indicates to the caller that the callee accepted the call. Now the caller has to confirm the call by sending a SIP ACK message.
Starting with this message, the user agents can communicate directly with each other. This bypasses the proxy server because the INVITE message and the 200 OK replies contain sufficient address information about both parties. However, the SIP�user agents may decide to continue signaling using proxy servers. The BYE request signals session termination. Either party can send it, and the other party must acknowledge it with a 200 OK reply.
For setting up the media session, the INVITE request and its replies may carry a payload specifying voice coder-decoder, transport protocol, port numbers, and further technical session information. Typically, the SDP�(Session Description Protocol, (Handley and Jacobson 1998)) is used to encode this media information.
SIP�incorporates elements from two widely deployed Internet protocols, namely HTTP (HyperText Transport Protocol, (Fielding et al. 1999)) used for the Web, and SMTP (Simple Mail Transport Protocol, (Klensin 2001)) used for sending email. From HTTP, SIP borrows the client-server design and the use of URIs (Uniform Resource Indicators). From SMTP, SIP borrows the text encoding scheme and the header style. A user is addressed with a URI similar to an email address. In most cases it consists of a user name and domain name (e.g. sip:user@foo.org).
SIP�functionality concentrates on just signaling. Its very simple design, restricted functionality, restricted usage of servers, and independence from other components of sessions make it highly scalable. SIP integrates well into the Internet architecture.
Another protocol suite for performing signaling has been developed by the ITU-T, namely H.323. Comparing SIP�with H.323 might go too far and might raise �religious� concerns. In general the functionality is very similar. SIP is considered simpler to implement mainly because of its text-based nature. On the other hand it has some performance problems, especially for SIP proxies since these need to handle high number of call setups. Additionally, the text representation is not so compact and might be a problem for wireless networks.
Given that a signaling protocol negotiates and sets up a multimedia session, the next step is sending the media data over the network. Designed for this task are RTP (Real-time Transport Protocol, (Schulzrinne 1996)) and RTCP (Real-time Transport Control Protocol, (Schulzrinne 1996)). RTP runs on top of UDP�(User Datagram Protocol, (Postel 1980)). RTP is the data transport protocol providing synchronization through time stamps, ordering through sequence numbers, and indication of payload type. The payload type defines the encoding of audio and/or video information.
The purpose of RTCP is to provide feedback to all participants in a session about the quality of the data transmission. It periodically sends reports containing reception statistics. Senders can use this information to control adaptive encoding algorithms, or it might be used for fault diagnosis and Quality of Service monitoring.
SIP�capabilities beyond the example above include call transfer, multi-party sessions, and other scenarios containing further SIP entity types and using further SIP message types. Section 5.3.2 describes the basic SIP functionality for session establishment and tear-down. In this section more advanced features of SIP are discussed. All of the features use a server in the network to provide the service, whereas SIP itself also works without server support.
SIP�allows a user to be at different places, which means that the user can have different IP addresses. The user is still reachable by an incoming call. Since a SIP address is a URI, the domain name can be resolved into a SIP server handling the session initiation (INVITE message). A SIP server (SIP Proxy) allows a user to register the current location (IP address) where the user can be reached. The SIP server receiving an INVITE message looks up the user�s registration and forwards the call to the registered place.
SIP�also allows redirection of calls. This means a server handling an incoming INVITE could reply that the person is currently not reachable via that server. It can give one or more possible other addresses that can be tried to reach the person. Such an address could be a different URI for the user, or a different server where the user potentially can be found. Concerning user mobility, in this case the server does not tell where the person really is. Rather the server indicates somewhere else that the person could be, or where more information about the location might be known. A SIP user agent of a caller then tries to contact the list of potential servers hosting that particular user.
The same feature can be used to implement group addresses. Calling a group address will redirect the call to a person available to take the call. This is one of the main functions needed for call center solutions.
SIP�can be seen as basic platform for service creation in many regards. The SIP servers for redirection, call forwarding, etc. can be extended to implement several other features still using the basic SIP protocol and SIP handling engine on the server. The service logic on SIP servers can influence the decision in various situations. Also, the user can influence these decisions by providing the SIP server with user-specific call preferences.
Through the flexible nature of SIP�and SDP, it is easy to extend SIP to provide completely different services. For example, a SIP server could be used as a game server bringing users together for distributed games. SIP then establishes a gaming session between several parties. This would mean SDP must be extended to contain game-specific information.
Since SIP�was inspired by several other protocols such as HTTP�and SMTP, it is easy to integrate with these systems to create combined services.
From a business point of view, the SIP�server need not be part of an ISP (Internet Service Provider) domain. Any company can provide SIP services by running a SIP server somewhere in the world. This means it is possible to decouple Voice over IP from base IP connectivity.
DEN (Directory-Enabled Networks) is a standardization activity by DMTF (Distributed Management Task Force). The main goal of DEN is to achieve better interoperability on the management data level. Additionally, it provides a standardized way for sharing management data among applications and service-providing elements.
DEN�tackles the problem of several islands of technologies, each of them maintaining its own management solution and system. It tries to overcome the traditional element-focused and technology domain-centric management, which hinders the integration of the technologies towards fully integrated networking solutions.
The key concept of the DEN�solution to management is that a service-enabled network is viewed as one entity. So everything including networking devices, computers, services, locations, organizational entities, and users are managed under a single framework. The key component in this concept is a central directory, where all management data is stored in a standardized way. Service management applications are now able to relate the management data, and can operate on it.
In order to standardize this vision, two different components are used. Firstly, it is necessary to standardize a remote directory access protocol. Secondly, the data model of the directory needs to be standardized.
The remote directory access protocol allows any management application component to remotely access the directory from any place, to read and to write management data. Naturally, the access needs to be secured. As access protocol, DEN�has chosen the LDAP (Lightweight Directory Access Protocol�, (Wahl et al. 1997)), currently in it third version. Meanwhile extensions and additions have been defined to overcome some of the deficiencies.
The Light Weight Directory Access Protocol was developed to simplify the complex X.500 directory�system (ITU 1993f). Initially, LDAP was meant to access X.500 servers in an easier way. Later, LDAP servers have been built as well.
The second component in DEN�is the standardization of the data model represented in the directory. A standard data model is used because different entities need to access the same data and need to understand what this data mean. Therefore the naming of data as well as the semantics of data must be standardized. DEN uses CIM (Common Information Model, (DMTF 1999)) as the basis for its standardized LDAP schemas.
The Distributed Management Task Force (DMTF) standardizes the Common Information Model (CIM). CIM is a database and directory-independent information model, defining only the pure data but no particular mapping to any implementation. CIM defines a whole set of classes together with their attributes. It defines associations and aggregation between the classes. A core information model predefines the overall structure of the model. From that core model several technology-specific models have been derived including physical components, network elements, applications and services. CIM is regularly updated and extended.
Given the standard CIM, LDAP schemas can be derived. Mappings to any data model representations are also possible. There needs to be a mapping function between CIM and an LDAP schema, because LDAP uses a more specific representation of data. The main mapping problems include the naming of objects and the representation of relationships modeled as associations in CIM.
DEN�has a very broad scope and tries to unify different worlds, which is always a very difficult task � even more when people from different companies need to agree on such a standard. For CIM�the problems lie in the standardization of a single information model. It is again difficult to agree on a high level of abstraction. In many cases a sound information model is the most valuable part in management software, so companies hesitate to participate in the standardization effort because they lose a competitive advantage.
The Open Services Gateway Initiative�(OSGi 2002) aims at specifying a service gateway in order to let small devices coordinate and cooperate. The target environments are mainly home networks. The major challenge is that there are many small devices such as smart phones, Web tablets and PDAs (Personal Digital Assistants), but also television sets, video recorders, camcorders, PCs, etc. in a home environment. Many of them are equipped with increasing networking capability. However, the communication facilities are heterogeneous and range from small wireless networks to high-speed wired networks.
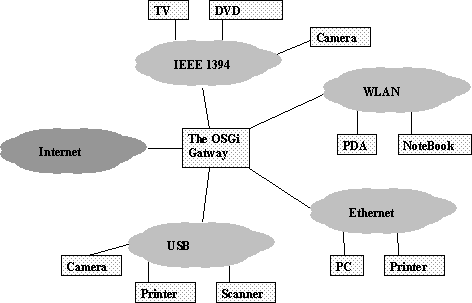
Figure 5.7: OSGi Home Network Scenario
To exploit the capabilities of these residential networks, the diversity of networks and devices must be coordinated. However, home users want to use the services without dealing with the control and management of the technology itself.
The approach of OSGi lies in providing a centralized OSGi gateway in the home as a coordination entity as well as a gateway towards the Internet. The specifications of the OSGi consortium define APIs (Application Programming Interfaces) that enable service providers and application developers to deploy and manage services in home networks.
The OSGi framework contains an embedded application server for dynamically loading and managing software components. These components can be dynamically instantiated by the framework to implement particular services. Additionally, the framework provides HTTP�support services, logging functionality, security, and service collaboration.
One of the most important features of the OSGi framework includes device discovery, service discovery, and self-management capabilities. Some of the underlying networking technologies already provide these functions. This is where OSGi can serve as a platform to interconnect these subnetworks of different technologies.
All these features aim at ease of operation for home networks, interoperation of several services, devices and applications in home networks, and their access to the Internet.
The following briefly discusses a new type of paradigm in networking, namely active networks. The technology is still in the research phase.
Assuming the future will be very service-centric in many regards, networks need to adapt to this paradigm. Note that the term �service� is quite overloaded with different meanings. Given this, new kind of networks need to focus on network services and the ability to easily provide these services. The following lists various observations known from other businesses that are, or will become, important in the networking area:
Assuming the service-centric business model is valid for the networking business as well, active networking may be a solution to the above requirements for new networks.
End-systems attached to a network are open in the sense that they can be programmed with appropriate languages and tools. In contrast, nodes of a traditional network, such as ATM switches, IP routers and Control Servers are closed, integrated systems whose functions and interfaces are determined through (possibly lengthy) standardization processes. These nodes transport messages between end-systems. The processing of these messages inside the network is limited to operations on the message headers, primarily for routing purposes. Specifically, network nodes neither interpret nor modify the message payloads. Furthermore, the functionality of a node is fixed and is changeable only with major effort.
Active networks break with this tradition by letting the network perform customized computation on entire messages, including their payloads. As a consequence, the active network approach opens up the possibilities of (1) computation on user/control/management data messages inside the network and (2) tailoring of the message processing functions in network nodes according to service-specific or user-specific requirements.
The paradigm of active networking can be applied on different planes. Figure 5.8 shows a three-plane network model including a data, a control and a management plane. The terminology in the area of active technologies is not yet uniform. Therefore many people talk about mobile code or mobile agents if the technology is applied for management purposes. Using active technologies in the control plane is often referred to as programmable networks.
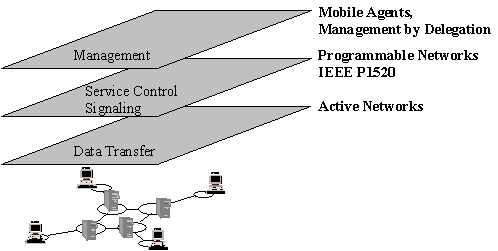
Figure 5.8: Programmability in Different Functional Planes
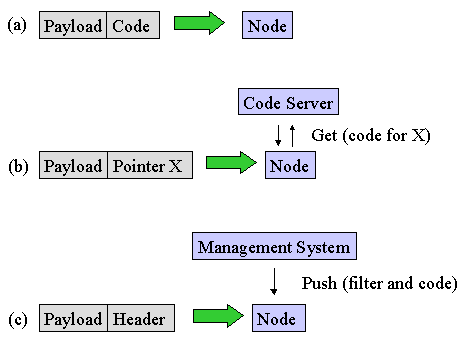
Figure 5.9: Code Loading Mechanisms
The mechanism to dynamically add new service functionality within the network is loading software code to the nodes. Three distinct methods exist ,together with variations of loading the code into the network nodes. Figure 5.9(a) shows the most extreme approach of adding processing code to each message. This is also referred to as the capsule-based, mobile agent, or integrated approach.
Figure 5.9(b) shows the second approach of adding just a pointer to code into the message header at a standardized place. The code is then fetched from a defined code server if it is not already available on the node.
Figure 5.9(c) shows the third approach of loading the code via a management action, so the network administrator is responsible for the specific code installed on the network nodes.
Different mechanisms for loading code have been introduced above. However the administrative entity installing the code was not specified. Note that the code loading mechanism is independent of the installer of the code, so the characteristics are orthogonal to each other. However, different combinations are superior to others in terms of implementation performance or complexity. Therefore they are often referred to as only one characteristic of active network architecture. There are three approaches: installation by a user/application, by a customer, or by the owner of the infrastructure. A user/application basically refers to the case where the code is installed by an end-system into the network, whereas a customer refers to a corporate network connected to a network provider.
A network user or a distributed application may install new message handling code into the network, typically on the path to its destination. This will allow an application vendor to include application-specific message handling code into the application. This will tailor the application for efficiency by including the networking part of the distributed application. This case is very easy to implement by adding the code to the messages. With other code loading mechanisms in place, there needs to be management interaction with the network or code server. One problem is the number of different pieces of code used in a network. This is very severe with this approach, because potentially every user is able to install new code into the network nodes. On the other hand, it allows for great flexibility because every user/application can flexibly change the network behavior.
In the literature of active networking, many application-aware network services are proposed that can profit from active networking technology. The following lists the basic network service scenarios used to enhance distributed application performance or reduce network resource consumption:
This chapter has outlined technologies used in IP-based environments to support services of various kinds. The technologies are very different, and are difficult to bring into perspective without a clear application scenario. All of them should be regarded as building blocks or a toolset for creating a service-enabled networking environment. Specific solutions have not been discussed, so the examples given only a sketch a potential roadmap for their deployment.
 Up one level to Wiley Book Page
Up one level to Wiley Book Page